Speech&Clone
Proje Galerisi
🎙️ Speech & Clone App
AI Destekli Ses ve Video İşleme Platformu
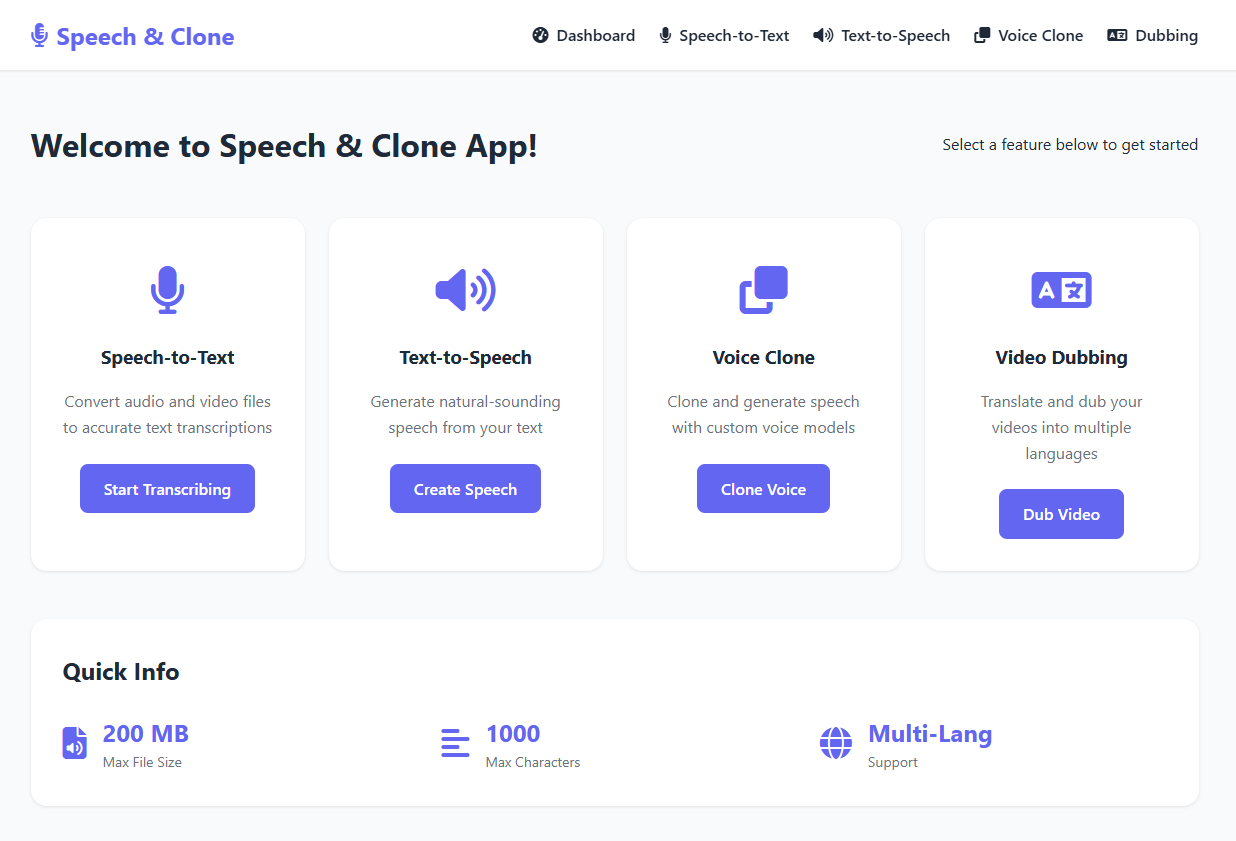
Speech & Clone App, yapay zekâ teknolojilerinin gücünü bir araya getirerek ses ve video içeriklerinde profesyonel işlemler yapmanızı sağlayan modern bir web platformudur.
OpenAI’ın Whisper ve TTS modelleri, MiniMax’ın ses klonlama teknolojisi ve FFmpeg’in güçlü medya işleme yetenekleri, tek bir çatı altında buluşur.
Bu platform, içerik üreticileri, eğitmenler, podcasterlar ve geliştiriciler için karmaşık AI süreçlerini sadece birkaç tıklamayla erişilebilir hâle getirir.
🚀 Temel Özellikler
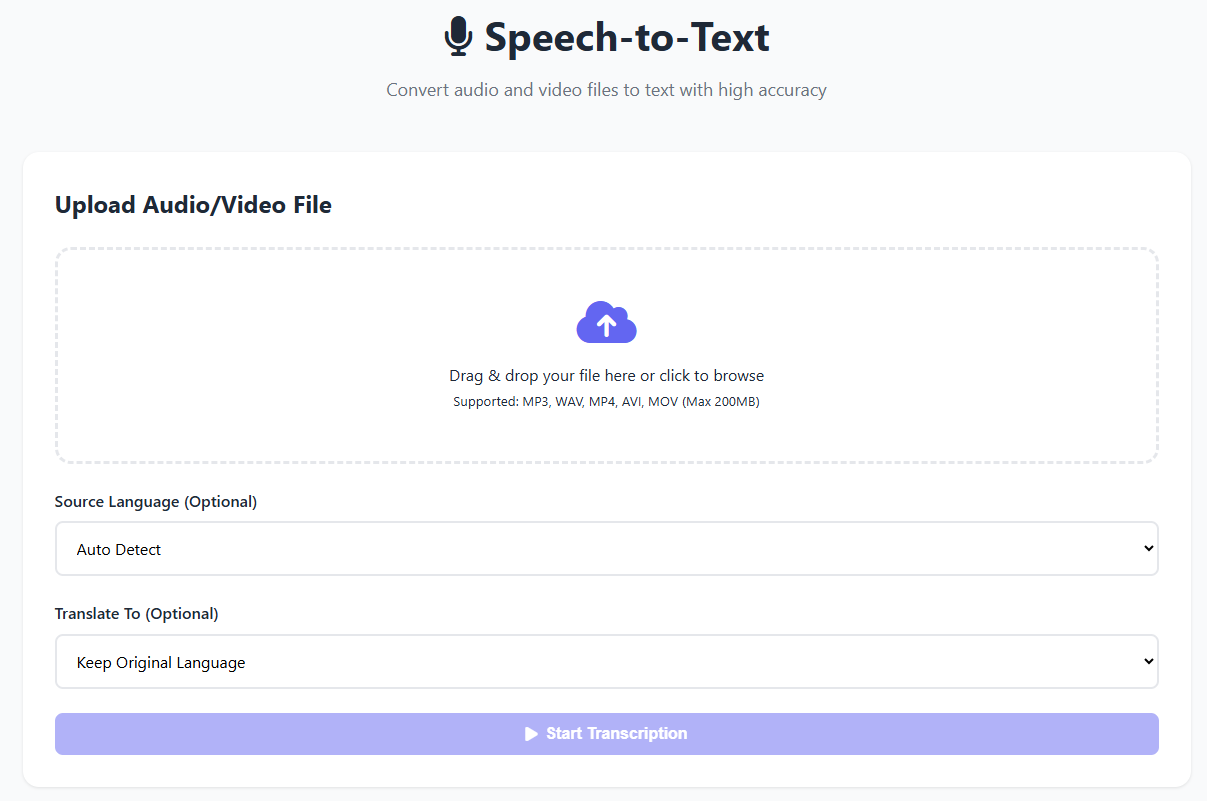
🗣️ 1. Speech-to-Text (Konuşmadan Metne)
OpenAI Whisper modeliyle 50+ dilde yüksek doğrulukta ses ve video transkripsiyonu.
Öne çıkan özellikler:
-
%95+ doğruluk oranı
-
MP3, WAV, OGG, M4A, MP4, MOV vb. destek
-
Zaman damgalı transkripsiyon (isteğe bağlı)
-
Büyük dosyalar için otomatik optimizasyon
-
FFmpeg ile ses temizleme
Kullanım alanları:
Podcast metinleri, toplantı kayıtları, altyazı üretimi, ses notlarının dökümü.
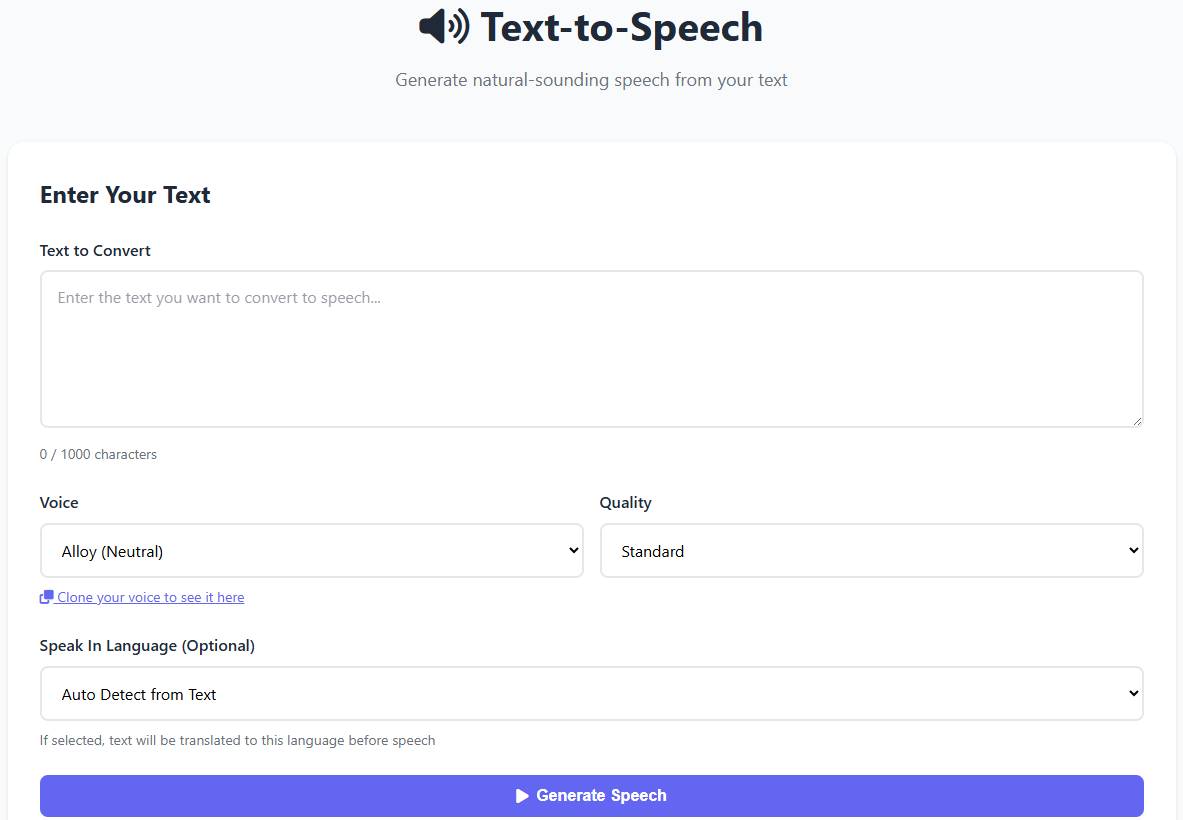
🔊 2. Text-to-Speech (Metinden Sese)
Metinlerinizi doğal, akıcı ve duygusal seslerle dönüştürün.
Desteklenen Ses Profilleri:
Alloy, Echo, Fable, Onyx, Nova, Shimmer
Teknik detaylar:
-
OpenAI TTS API (tts-1 & tts-1-hd)
-
44.1kHz HD kalite seçeneği
-
1000 karaktere kadar metin desteği
-
Otomatik dil çevirisi (GPT-3.5-Turbo)
Kullanım alanları:
Sesli kitaplar, e-öğrenme içerikleri, podcast girişleri, çok dilli pazarlama seslendirmeleri.
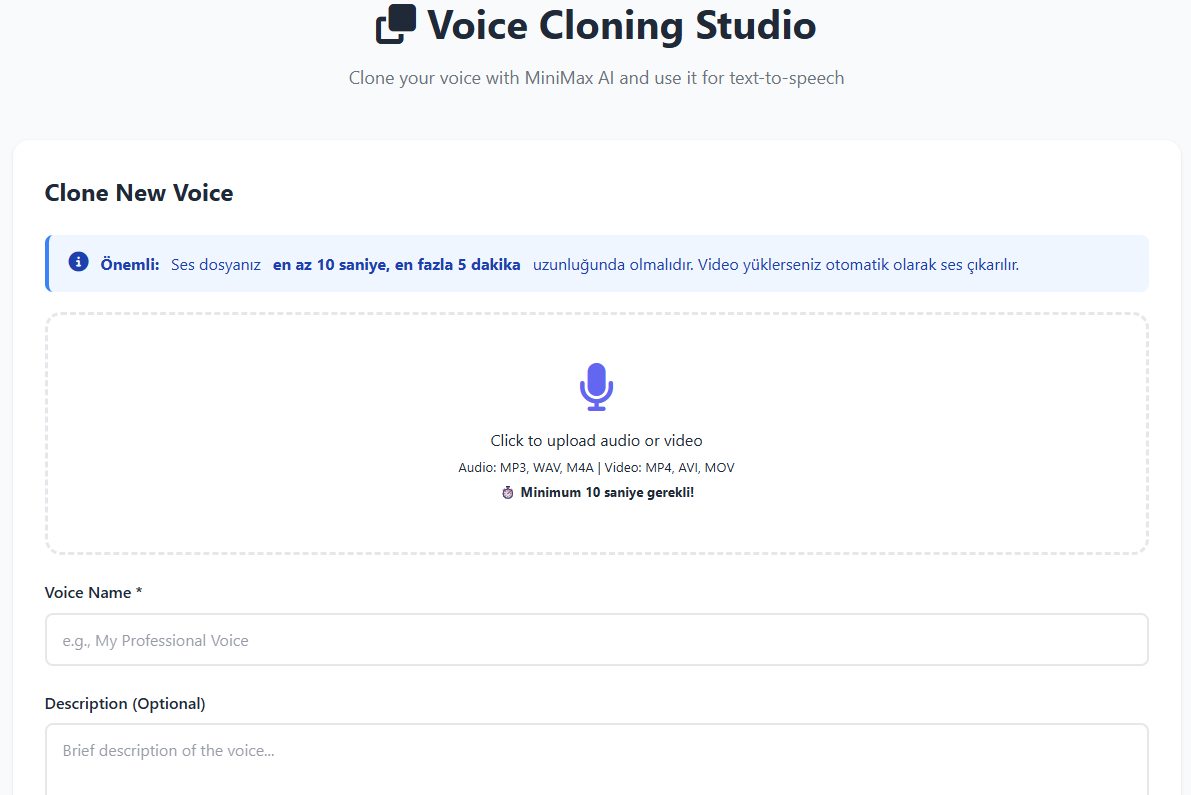
🧬 3. Voice Cloning (Ses Klonlama)
MiniMax API ile gerçekçi ve kişiye özel ses profilleri oluşturun.
Özellikler:
-
10 saniye–5 dakika arası ses örneğiyle klonlama
-
MP3/WAV/M4A desteği
-
FFmpeg tabanlı ses optimizasyonu
-
Sınırsız voice_id oluşturma
-
Yüksek benzerlik oranı (%85–95)
Kullanım alanları:
Marka sesi oluşturma, karakter seslendirme, memorial ses projeleri, çok dilli içerikler.
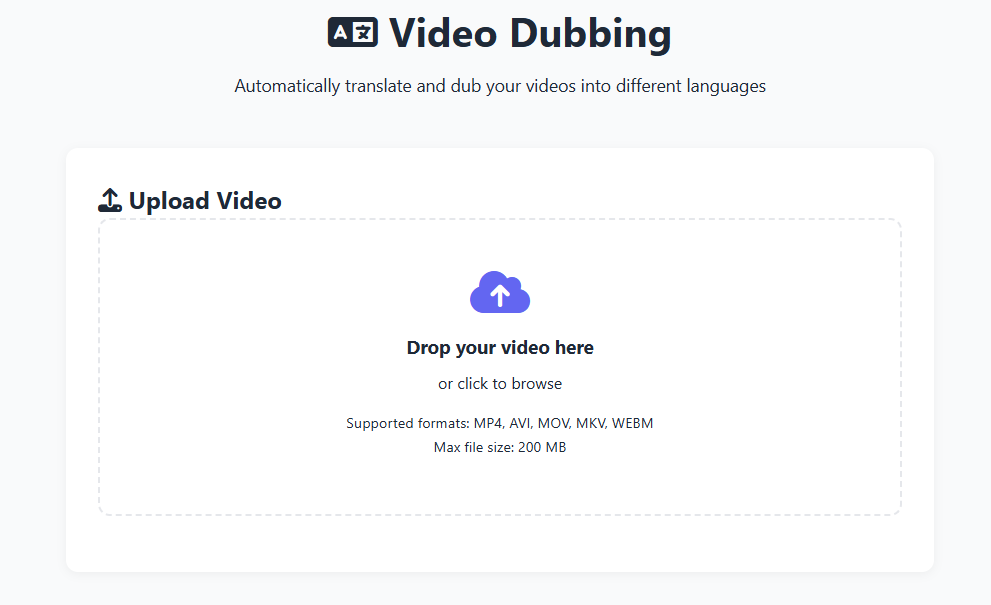
🎬 4. Video Dubbing (Otomatik Dublaj)
Videolarınızı farklı dillere otomatik olarak çevirin ve yeniden seslendirin.
6 Aşamalı Süreç:
-
Ses çıkarma
-
Transkripsiyon (Whisper)
-
Çeviri (GPT-3.5)
-
Ses üretimi (TTS veya klonlanmış ses)
-
Hız & senkron ayarı
-
Video birleştirme
Destek:
-
50+ dil
-
H.264 video, AAC ses codec
-
Otomatik senkronizasyon
-
Klonlanmış ses veya standart TTS sesi seçimi
Kullanım alanları:
YouTube çoklu dil versiyonları, e-öğrenme, reklam lokalizasyonu, global sosyal medya içerikleri.
🛠️ Teknik Altyapı
Backend: Python 3.9+, Flask 3.0, FFmpeg
AI & API Entegrasyonları:
-
OpenAI Whisper (STT)
-
OpenAI TTS
-
GPT-3.5 Turbo (çeviri)
-
MiniMax Voice Clone
Diğer Teknolojiler:
Requests, Pillow, Flask-CORS, imageio-ffmpeg, dotenv
🏗️ Mimari Yapı
Katmanlı ve modüler yapı:
-
routes/: API endpoint’leri -
services/: AI işlem mantıkları -
utils/: Yardımcı fonksiyonlar -
templates/&static/: UI ve frontend dosyaları
Veri Yönetimi:
-
Session-based yapı (veritabanı gerekmez)
-
Hızlı deployment
-
Privacy-first yaklaşım
🔒 Güvenlik
-
Environment değişkenleriyle API key koruması
-
Dosya tipi & boyut validasyonu
-
Path traversal koruması
-
Otomatik geçici dosya temizliği
-
Kalıcı veri depolama yok → Sıfır veri sızıntısı riski
⚡ Performans
-
FFmpeg hızlandırmalı dosya işleme
-
Büyük dosyalar için otomatik sıkıştırma
-
300 saniye API timeout
-
Memory ve temp dosya optimizasyonu
Ortalama işlem süreleri:
-
STT (1 dk ses): 5–10 sn
-
TTS (100 karakter): 2–3 sn
-
Voice Clone: 30–60 sn
-
Dublaj (1 dk video): 30–90 sn
🔮 Yol Haritası
Yakında eklenecek özellikler:
-
WebSocket ile gerçek zamanlı transkripsiyon
-
Çoklu dosya işleme (batch processing)
-
Gelişmiş online editor
-
Bulut depolama entegrasyonu (S3, Drive)
-
Kullanıcı hesapları & raporlama paneli
-
Emotion-based TTS ve Voice Style Transfer
💡 Proje Değeri
Kullanıcı için:
-
Manuel işleme göre 10 kat daha hızlı
-
Abonelik gerektirmeden profesyonel kalite
-
Basit arayüz, teknik bilgi gerektirmez
-
Gizlilik odaklı tasarım
Teknik olarak:
-
Modern AI API entegrasyon örneği
-
Scalable Flask mimarisi
-
Gerçek dünya kullanımına hazır modüler kod
👨💻 Geliştirici
Sadıkcan TULUK
📧 sadikcantuluk@gmail.com
🌐 sadikcantuluk.online
Teknolojiler: Python, Flask, OpenAI, MiniMax, FFmpeg, Whisper, GPT-3.5, REST API, HTML5, CSS3, JavaScript
Lisans: İç geliştirme & test aşamasında.
Gelecekte open-source veya ticari lisans planlanmaktadır.
🎓 Sonuç
Speech & Clone App, AI destekli ses ve video işleme süreçlerini demokratikleştiren yenilikçi bir platformdur.
Karmaşık yapay zekâ teknolojilerini kullanıcı dostu arayüzlerle birleştirerek, ses ve video üretiminde profesyonel çözümleri herkes için erişilebilir kılar.
Gerçek dünya problemlerine odaklanan, ölçeklenebilir ve sürekli gelişen bir projedir.